RankRecon
See what's winning on Google. And what's missing.
RankRecon is an SEO browser extension that extracts Google search results and analyses each page for 25+ data points including content metrics, link profiles, and trust signals.

Why Use RankRecon?
RankRecon is designed to save you opening 10 tabs and manually wading through sites to try to understand the competition. Get all the data and analysis you need straight from the actual SERP.
Skip the manual audit
Titles, meta descriptions, H1s, word counts, link profiles, and schema for every page in the SERP, in seconds.
See what's winning
Long-form guides or quick listings - the content pattern Google rewards for any query.
Spot the gaps
Topics, schema, or trust signals no one in the top 10 is using yet.
Snapshot a SERP
Before it changes, or your client asks why it did.
How It Works
1. Search Google
Navigate to any Google search results page.
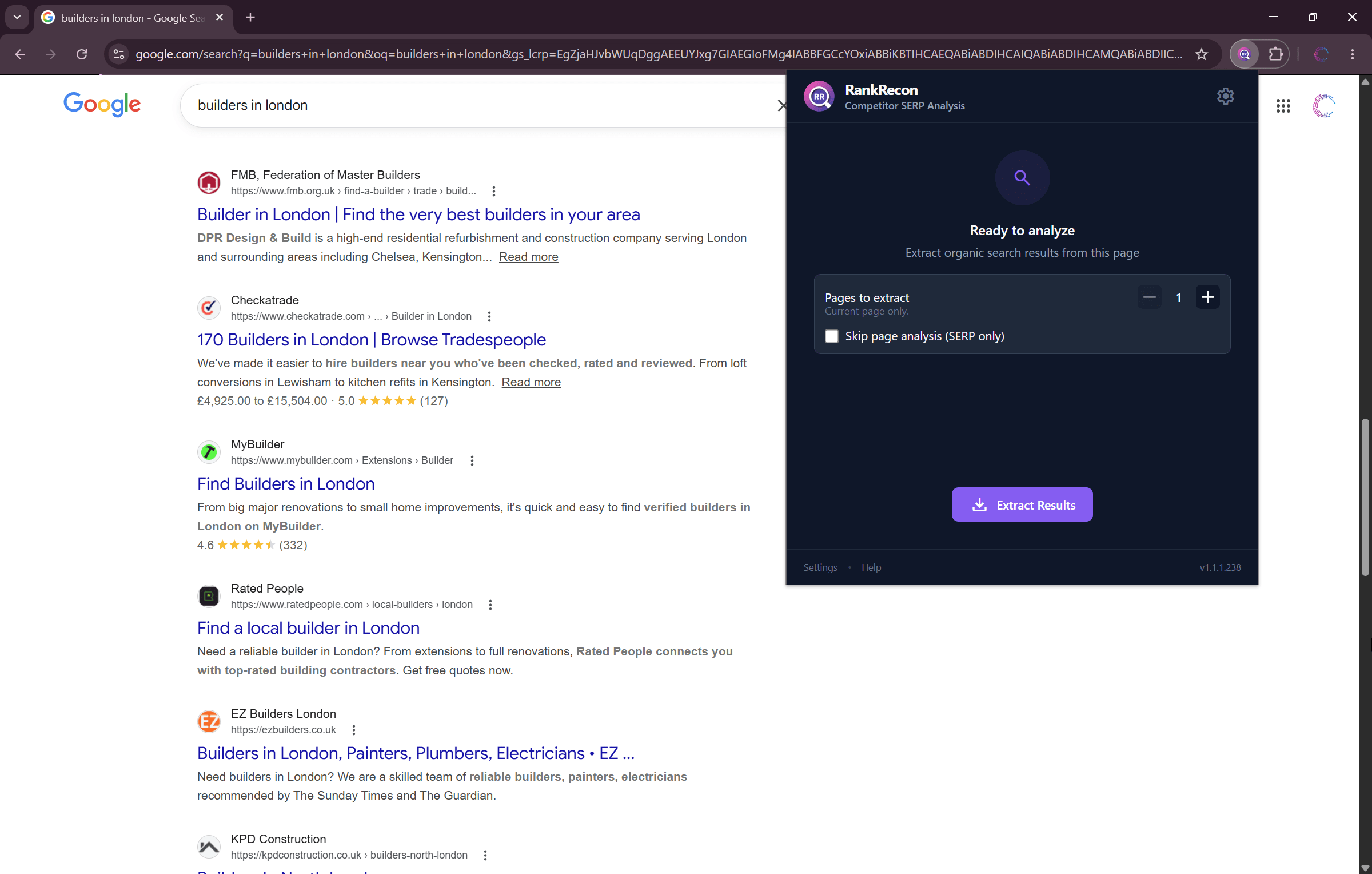
Open google.co.uk and search 'builders in london'. Click the RankRecon icon in your toolbar to open the analysis panel. Choose how many SERP pages to process and click to get started.
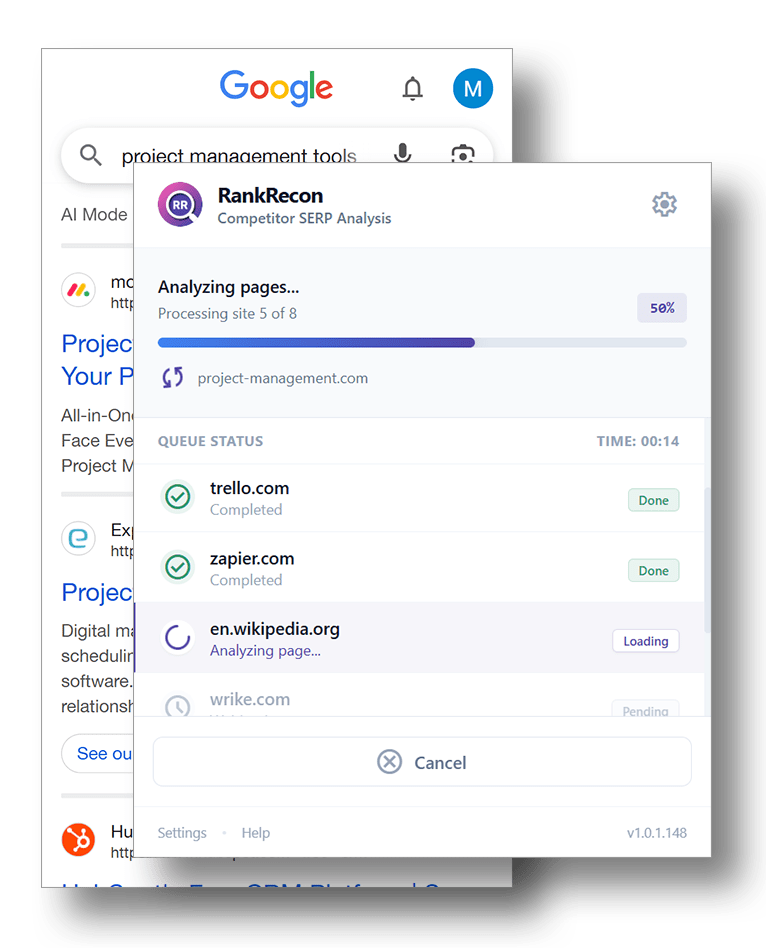
2. Extract Results & Analyse Pages
Click to extract results from the SERP and analyse each site individually.
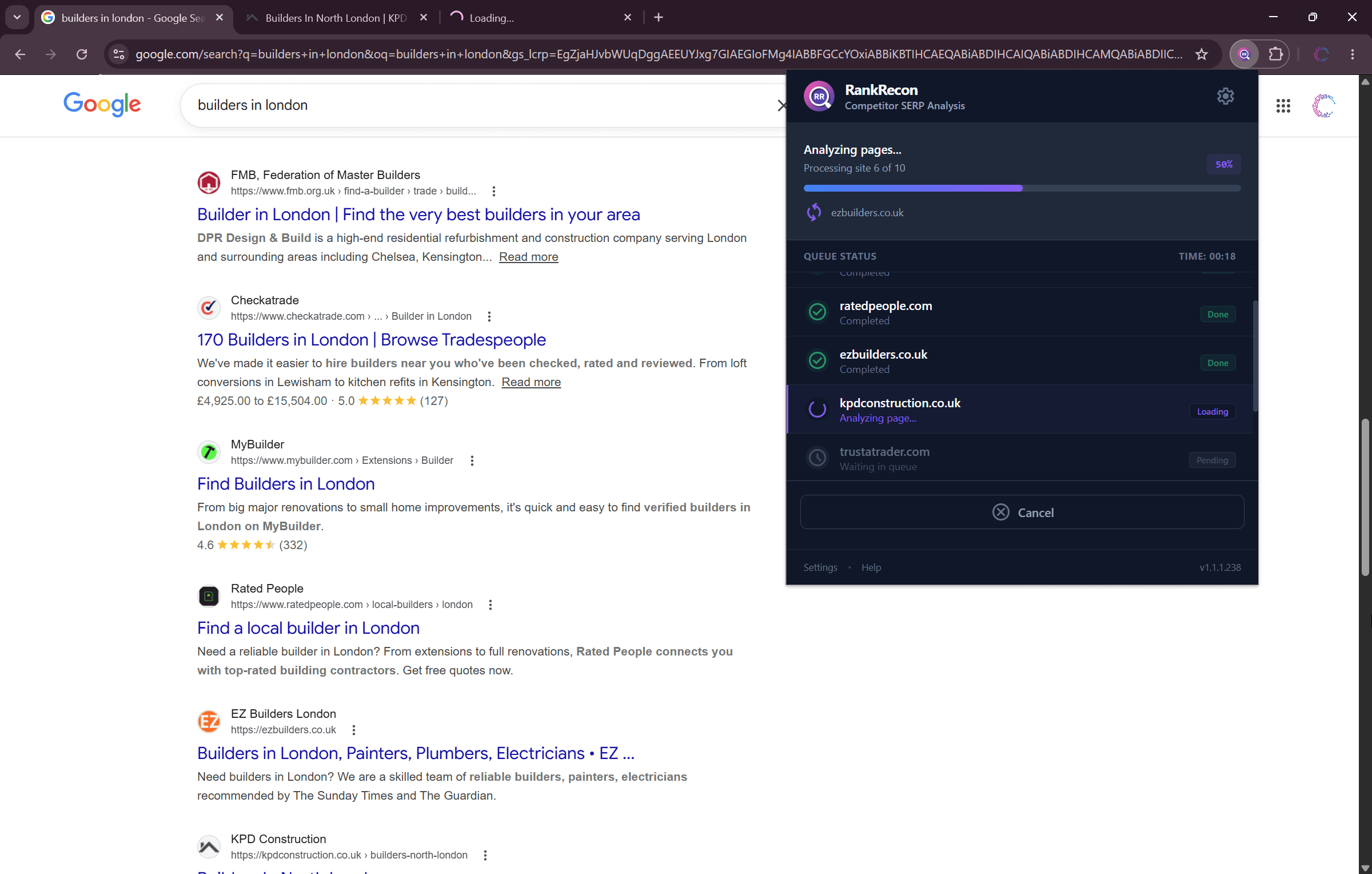
RankRecon filters out ads, shopping cards, and other Google features, then queues each organic result for scraping. You'll watch each page get extracted in real time with titles, meta descriptions, H1s, word counts, link profiles, schema markup, and more, pulled from the live page.
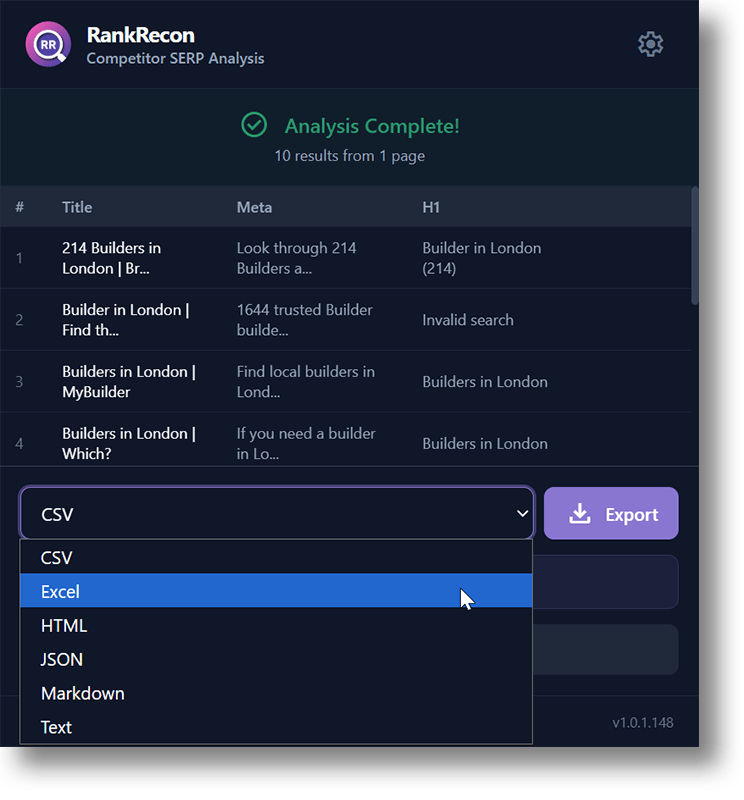
3. Export Data
Save out all data from the SERP for further analysis, or as a snapshot of the SERP composition in this moment.
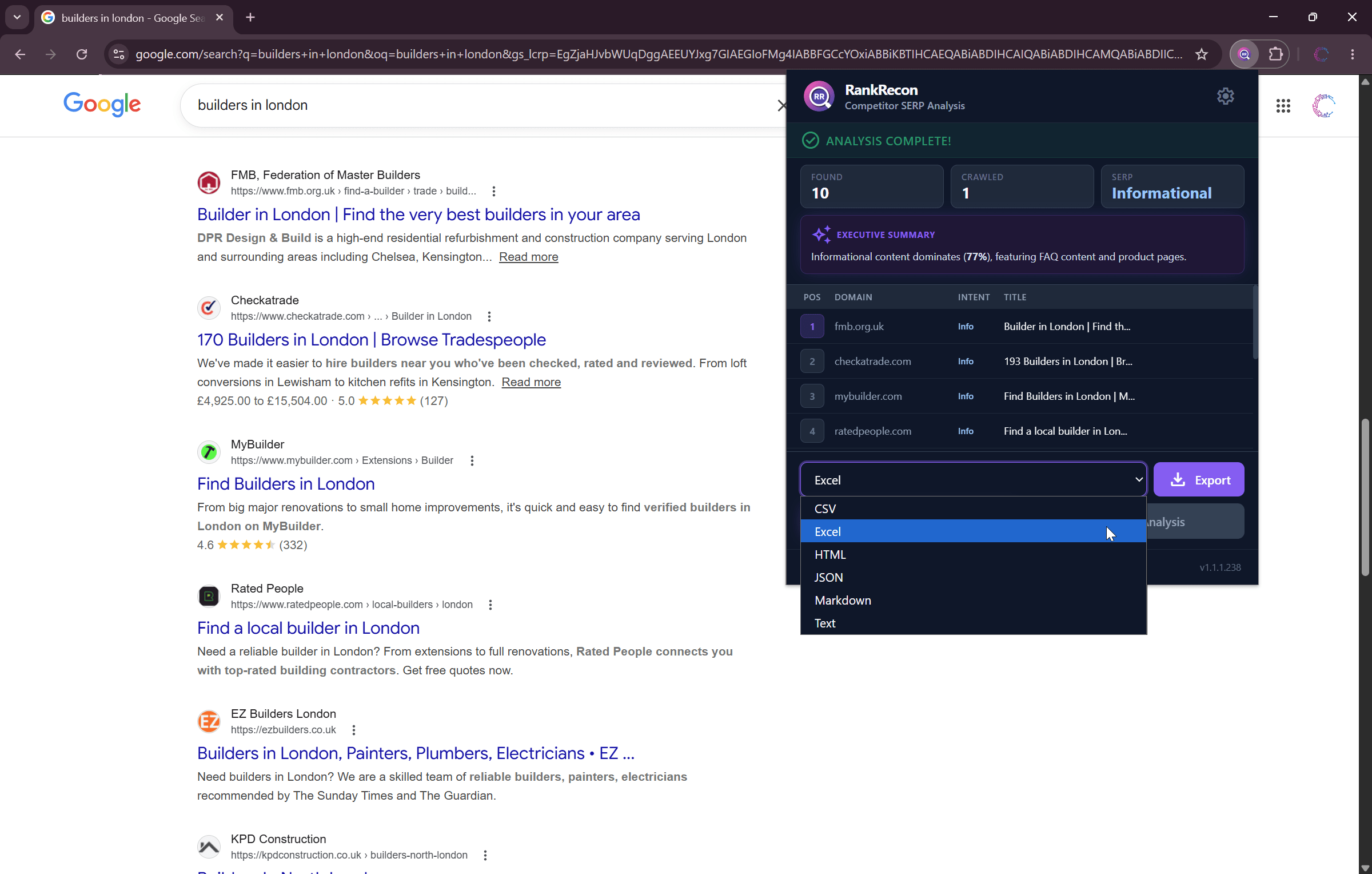
Export the full dataset to whatever data format works best for you - CSV, Excel, JSON, Markdown, HTML, or Plain Text. You can then analyse any of 25+ data points for the SERP and the sites in it.
4. View Page 1 Analysis
Get quick insights into the composition of the SERP and the type of sites that Google is rewarding.
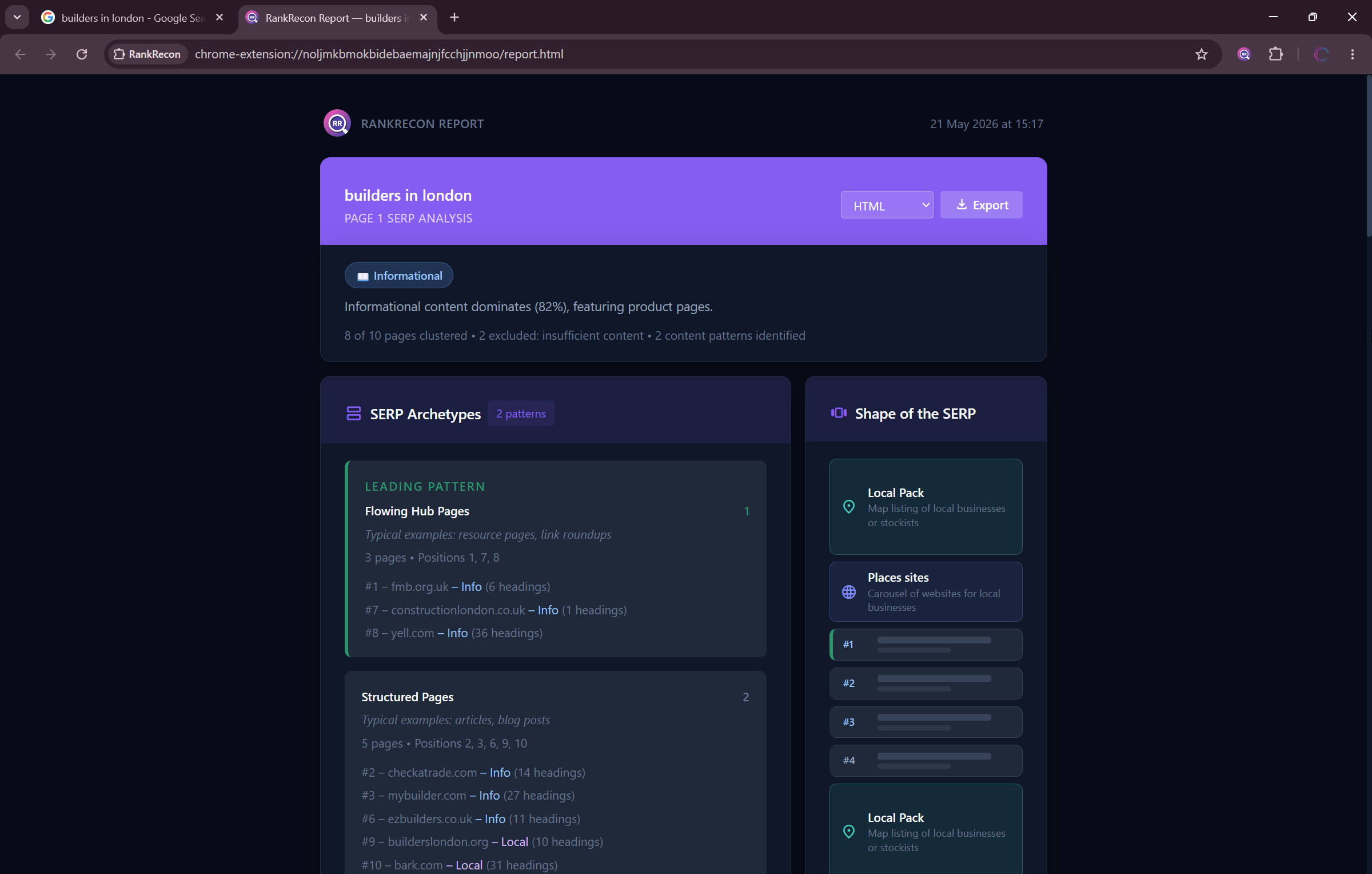
Open the Page 1 analysis report for a full breakdown. What content archetypes are winning (listicles, long-form guides, local pages), what do the top results have in common, and a build checklist of features to include to compete in this SERP.
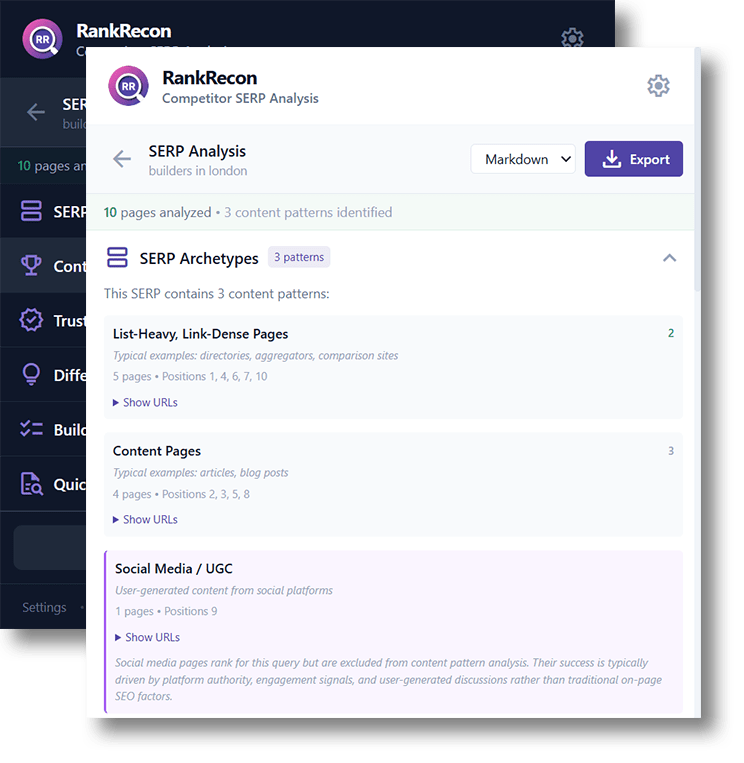
Page 1 Analysis Report
Generate a detailed report that breaks down what the top-ranking pages are doing and what you need to compete.
SERP Composition
Understand what type of SERP you're looking at and what type of sites are winning it.
Shape of the SERP
Visualises the full layout of page 1 - organic results interleaved with ads, AI Overviews, Local Packs, videos, and more.
Archetype Detection
Groups pages by content pattern - listicles, guides, tools, homepages - so you can see what format Google rewards.
Content Targets
Recommended word count, heading structure, and image usage based on what's working for the top results.
Trust Signals
Compares adoption of schema markup, contact forms, video, table of contents, and other credibility factors.
Differentiation Opportunities
Identifies low-adoption features you could add to stand out from competitors.
Build Checklist
Auto-generated action items based on the analysis - a ready-to-use brief for your content.
Why I built RankRecon

By Daniel Betts
The big SEO platforms absolutely have their place, but they're not cheap, you have to work within their constraints, and they're not the real SERP, they're an abstraction of it.
No matter how much insight they gave me, I never had the feeling that I truly understood the SERP. I always needed to go and see the real SERP and what the actual sites in it looked like, before I could make a plan of action.
But manual research is messy (tabs everywhere) and the 'feel' I'd built up for a SERP would fade fast. A month later I'd find myself doing the same investigation again.
So I needed a tool to tell me about the SERP - what are the sites Google is rewarding, what is their composition, what do the ones that are doing well have in common? RankRecon is built to answer these questions.
It was built with a particular philosophy in mind:
- It runs against the actual SERP, not abstracted data
- All processing happens locally, in your browser
- You can save out what you find, for next time
I still use the big platforms for the rest. But for the "feel" of a SERP, I open up RankRecon.
Privacy by design
All analysis happens in your browser, against the SERP you're already looking at. RankRecon doesn't need to know anything about you to work, so it doesn't ask for it.
No accounts, no tracking
Optional error reports contain no personal data.
Minimal permissions
Only requests what's needed to function.
Local processing
All analysis happens in your browser.
Frequently Asked Questions
When you click the RankRecon button on a Google search results page, it does three things, one after the other.
First, it reads the SERP. It works out which results are the actual organic ones. It filters out ads, the map pack, "people also ask" and just hones in on the ranked pages.
Then it goes and visits each of those pages in turn, opening a tab to load the page in the background. It analyses the page to pull data that gives us a useful summary of the content - title, H1, headers, links, word count, schema, and so on. Everything you see if you export the data.
Once it's got the data, it takes it all and looks for patterns. Which pages have a similar shape? What does Google seem to be rewarding here? What's the dominant style? It sorts the results into a handful of patterns - we've called them "archetypes" - and tells you which one is winning.
The whole thing runs in your browser. Nothing gets sent off to a server, no AI is involved, no big database in the cloud. It's just looking at what's already on the page in front of you and drawing some sensible conclusions. And that's why it can also be a bit wrong sometimes (see the next question). It doesn't know anything about the wider web, it only knows what it could see when it looked.
It depends what you mean.
The data collection? It's largely exact. It's reading the pages and seeing what's there. The only wrinkles are that it has to filter out some stuff - cookie popups, for example, will skew the content counts for a page and negatively affect classification (and you would be amazed by how much sometimes). So we have to filter those out, and there may be some edge cases where it might fail. The rest of the time - it's counting what's on the page and it should be correct.
The archetype grouping and intent labels? Less accurate. But perfect accuracy is not the goal.
Because it runs locally and isn't connected to AI, it's relying on collecting data from each site and then making some pattern-based groupings based on that data. Without RankRecon, you're looking at 10 sites that all look the same in the organic results. With it, you're now looking at data points and potential intents. It might be a bit fuzzy, but a pattern should be revealing itself.
That pattern is designed to give you the feel for a SERP that otherwise would have required your own manual research.
That's the ethos of the tool. It didn't scrape the whole internet and then charge you a large monthly subscription for an answer like the big SEO tools. Instead it used the 80/20 rule - the 20% of the effort that gets you 80% of the way there - pulling data straight out of the SERP and giving you an instant feel for what's there.
So each run, you're going to see a site that probably should have been in the other archetype, or where the intent is off (which is usually because the site used an inappropriate schema, or has some weird structure that doesn't really match what you might expect for that type of site) - but you, the human, can start to see the pattern anyway.
It's not perfect, by design it can't be. But it gives you insight, quickly and for free - that's what it's built to do.
All wrong, or a bit wrong?
First, make sure you've read the previous question. If it did a really bad job, please let me know. There's an infinite number of SERPs out there, and I haven't quite got around to testing them all yet. If people can send me examples of when it really does badly, it will help me fix up the gaps.
There really isn't one. I built RankRecon for my own use. I'm putting it out into the world in case it's useful to other people.
If it is, then it's possible it might become freemium in future - I'd like to add more features, but only if there's demand for them. If it ever does become freemium then it won't be by removing existing functionality, that will always stay free. So what you see now you'll carry on getting for free, no catch.
As for collecting your data, I'm just not that interested in you. Sorry!
Currently Chrome and Firefox. If you want support for another browser, let me know here. If there's enough demand I'll add it.
Not currently, it's just designed for Google. If there's enough demand I could add it. Let me know here.
I don't know yet, because so far it hasn't happened. I imagine something like the following scenario will play out:
- People will shout at me.
- I'll see that RankRecon has completely stopped working - if Google changes the SERP, it won't be able to determine the organic results, and that breaks everything downstream of that (EVERYTHING is downstream of that!).
- I'll panic for a bit. Not sure how long that will last or quite what form it will take.
- I'll get to work. Pure adrenaline will probably make sure it gets done pretty rapidly. Given that it's just a change to the HTML of the SERP, it's going to be a case of modifying RankRecon for the new HTML structure, i.e. it shouldn't take very long.
- I'll push a fix.
- Firefox will go through almost immediately. Chrome will take 1-3 days, because they're a bit on the slow side.
- Hopefully everyone will now stop shouting at me, and I will go and have a lie down.
Because a fetch would get you the raw HTML only. Given how much of the web is now driven by JavaScript frameworks, the percentage of sites that would be left unreadable by the tool would be high and would only grow in the future. That would mean no data for those sites and make what we're doing impossible, removing any ability to have any insight into the SERP.
So, we do a tab load and give the page the time it needs to load, and then a moment longer to render fully. Then we can read the data from the page exactly as you would see it. That gives us the accurate data that everything else depends on.
If you use it for any length of time, you're going to come across sites that don't load, sites with bot protection, and other assorted weirdness. When processing has finished, these sites will show up listed as "Error" in the results table.
Two ways to handle these.
- There's a button to retry all sites that failed. Click it, give it another go. Sometimes that will resolve it.
- If not, the best thing to do is find the site with the error in the results table. Click the "Open" link next to the site and go have a look. It might just be slow loading. It might have Cloudflare or some other bot protection, fill in the captcha. Once the site has resolved, head back to the SERP page and open RankRecon again. Click the "Redo" button next to the site and it will read the data from the open tab. That will now succeed. You can close the tab and carry on.
RankRecon reads the search results page that's already open in your browser. If you've asked it to pull in further pages (up to page 10), it'll fetch those too - but it does that by loading them the same way you would if you clicked "Next" yourself. No special requests, no bulk scraping, no shortcuts. Just standard browser page loads in your own session, one after the other.
It doesn't modify the results, inject anything into them, or pretend to click on things either. It just reads what's there.
Where it does generate more traffic is on the competitor sites - it opens each of those result URLs in a background tab to have a look. That's the same as you opening each one in a new tab yourself, which is what you'd probably be doing if you were checking the competition manually. Just a bit quicker.
The one thing worth flagging: if you ran it across loads of SERPs back-to-back (especially with multi-page on), Google might eventually show you a captcha. That'd be because of the cumulative searching, not because of anything sneaky RankRecon is doing. It's just doing what you'd do yourself, in your own browser session.
Get RankRecon
Download the extension for your browser - it's lightweight and installs in seconds. Start analysing the SERPs immediately.